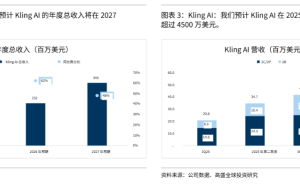
快手近日正式开源了其最新一代多模态大模型Keye-VL-671B-A37B,这款基于DeepSeek-V3-Terminus架构的模型拥有6710亿参数,在视觉感知、跨模态对齐和复杂推理能力上实现了显著突破。通过系统化的预训练和后训练策略,该模型在通用视觉理解和视频理解领域展现出超越同类产品的性能表现。
在图像识别测试中,Keye-VL-671B-A37B展现出惊人的细节捕捉能力。当面对三张票据的识别任务时,模型不仅准确识别出文字和版式差异,更通过逻辑推理判断出其中仅有两张为电影票,第三张实为食品兑换券。这种超越表面识别的深度理解能力,源于模型对视觉元素与语义信息的精准关联。在视频理解测试中,该模型能精准捕捉"蓝色双层电车"等核心元素,并完整复现镜头运动轨迹和场景转换细节。
性能对比数据显示,在26项主流基准测试中,新模型在18项指标上取得领先成绩。特别是在STEM、推理、视频理解等复杂任务领域,其表现超越字节跳动Seed1.5-VL think和阿里Qwen3-VL 235B-A22B等前沿模型。这种优势得益于其独特的三阶段预训练体系:首阶段冻结视觉与语言模块,专注特征对齐;次阶段全参数训练;末阶段通过退火训练强化细粒度感知。整个过程仅使用300B高质量数据,相比其他动辄万亿级的数据规模,展现出更高的训练效率。
后训练阶段采用创新的混合数据策略,将指令数据与长思维链(Long-CoT)数据按特定比例融合。实验表明,这种组合使模型在保持指令响应能力的同时,显著提升复杂推理的稳定性。技术团队开发的严格数据筛选流程,有效过滤了冗余反思内容,确保思维链数据的精炼性。在强化学习环节,模型采用阿里Qwen3系列同源的GSPO算法,通过序列层建模提升训练稳定性,并配备专用Verifier模型验证推理逻辑,使答案准确率提升显著。
该模型现已在Hugging Face和GitHub平台开放下载,开发者可访问指定链接获取完整代码库。其视觉编码器继承自今年9月开源的Keye-VL-1.5模型,该80亿参数版本已支持128k tokens上下文扩展。技术文档显示,新模型在多模态数学数据集上的平均准确率提升达1.33%,在开源感知基准测试中提升1.45%,展现出强大的跨领域适应能力。
通过持续优化数据管线,快手构建了覆盖OCR、图表、表格等复杂格式的自动化处理流程。这种系统化训练方法使模型能准确解析视觉信号中的关键信息,为后续开发多模态Agent能力奠定基础。当前版本已具备基础工具调用能力,未来将强化在真实场景中的自主推理与任务执行能力,推动多模态系统向更实用的方向发展。