近期,科技界传来一则引人注目的消息,英伟达研究团队在人工智能领域取得了重要突破。据科技媒体marktechpost报道,英伟达不仅推出了一种名为ProRL的强化学习方法,还成功开发出了目前全球顶尖的1.5B参数推理模型——Nemotron-Research-Reasoning-Qwen-1.5B。
推理模型,作为专门设计的人工智能系统,其核心在于通过复杂的长链推理过程,得出最终的答案。这一技术在近年来备受关注,而强化学习在这一过程中的作用更是不可忽视。此前,DeepSeek和Kimi等团队已采用可验证奖励的强化学习方法(RLVR),推动了GRPO、Mirror Descent和RLOO等算法的发展。
然而,尽管强化学习在理论上被认为能够提升大型语言模型(LLM)的推理能力,但实际应用中却面临诸多挑战。现有研究表明,RLVR在pass@k指标上并未显著优于基础模型,这显示出推理能力的扩展存在局限性。当前的研究大多聚焦于数学等特定领域,导致模型过度训练,限制了其探索新领域的潜力。同时,强化学习的训练步数通常较短,往往仅数百步,这使得模型难以充分发展新的能力。
为了克服这些难题,英伟达研究团队推出了ProRL方法。他们不仅将强化学习的训练时间延长至超过2000步,还大大扩展了训练数据的范围,涵盖了数学、编程、STEM、逻辑谜题和指令遵循等多个领域,共计13.6万个样本。这一举措旨在提升模型的泛化能力,使其能够在不同领域都表现出色。
在ProRL方法的基础上,英伟达团队采用了verl框架和改进的GRPO方法,成功开发出了Nemotron-Research-Reasoning-Qwen-1.5B模型。这一模型在多项基准测试中均表现出色,超越了基础模型DeepSeek-R1-1.5B,甚至在某些方面优于更大的DeepSeek-R1-7B模型。
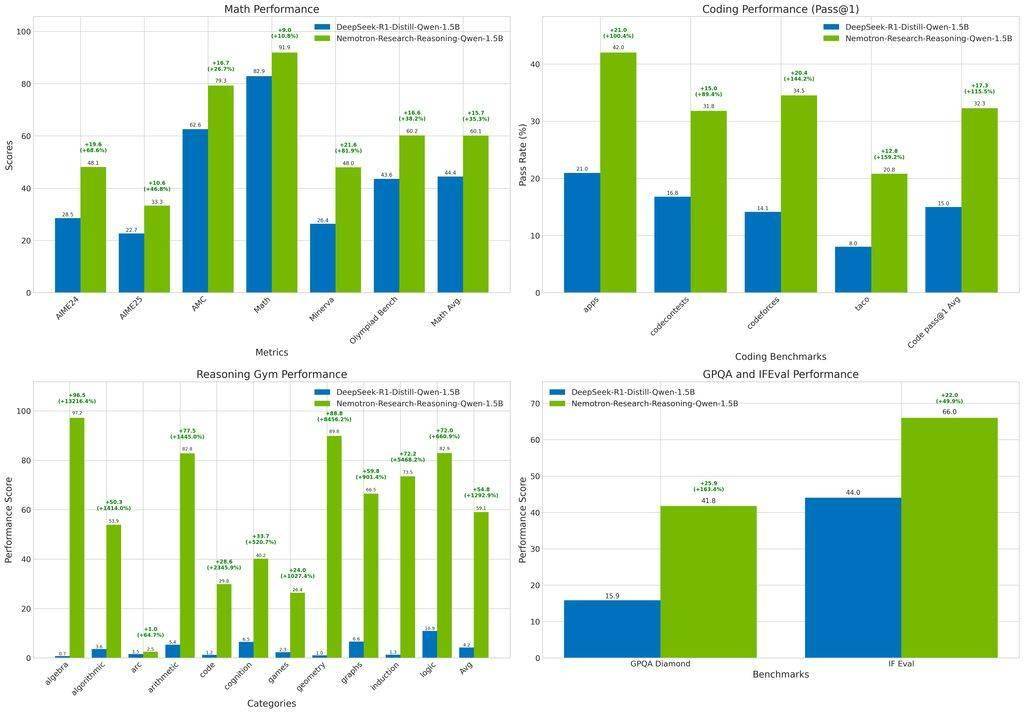
测试结果显示,Nemotron-Research-Reasoning-Qwen-1.5B模型在数学领域实现了平均15.7%的提升,编程任务的pass@1准确率提高了14.4%,在STEM推理和指令遵循方面分别提升了25.9%和22.0%,逻辑谜题的奖励值更是提升了惊人的54.8%。这一系列数据充分展示了该模型在不同领域中的强大推理能力和泛化性能。
英伟达的这一突破无疑为人工智能领域带来了新的希望和可能。随着技术的不断进步和应用的不断拓展,我们有理由相信,未来将有更多像Nemotron-Research-Reasoning-Qwen-1.5B这样的优秀模型涌现出来,为人类社会带来更多的便利和价值。